Hello!
We are currently facing some issues with the Joulescope JS220 we’d hope for some input on. I wrote some code to make a thread read data from the Joulescope, which we want to use as part of our Pytest based test framework. This code fails within approx. 1 hour due to the the attached error. Some of the error messages are unfortunately in Norwegian (thanks Windows!), but translates to
WinUsb_GetOverlappedResult error 31: A device connected to the system does not work
and
WinUsb_GetOverlappedResult error 31: A device was listed that does not exist.
Seems to me like the Joulescope is suddenly powered off or something. Power to DUT is also cut.
Excerpt from the code is here: Joulescope sample script - Pastebin.com
This is based on the simple example from the ReadTheDocs documentation. This instantiates the joulescope, creates a callback function to get the data and hands off that callback to a separate thread for periodic logging using my DictLogger class.
I noticed from other posts in this forum that my approach here was maybe a bit overkill, as I’m probably using the full data rate of the Joulescope?
We need the Joulsescope to do some long running logging over approximately 30 hours, so this needs to be rock solid. We need samples with 1 or 0.5 second intervals of current, voltage and power. Getting the mean over the intervals is probably better than just 1 sample so we don’t accidentally miss huge spikes. Joulescope is connected directly to USB port on HP Elite Desk running Windows 10 with Python 3.10.
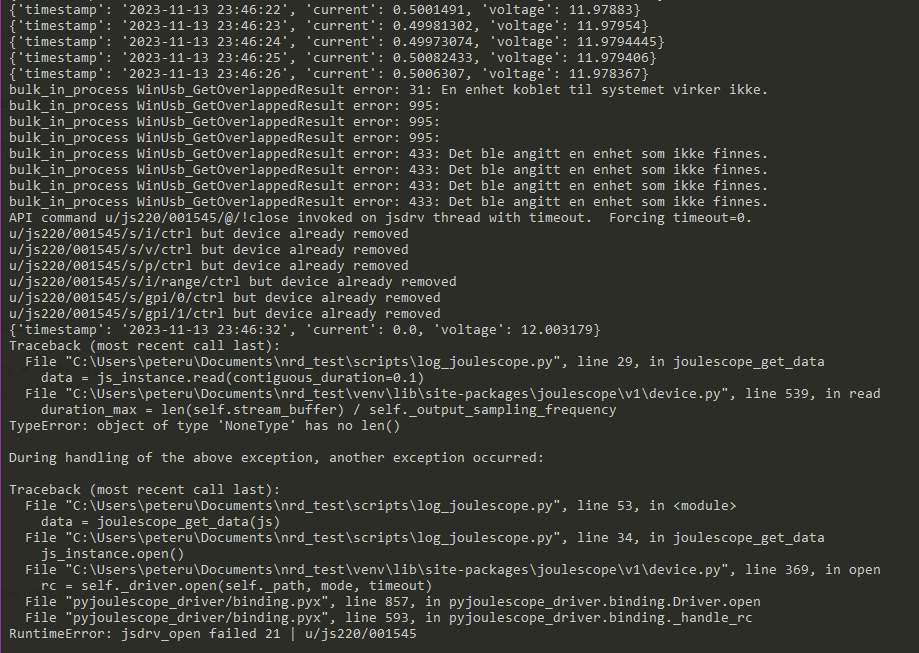
As a intermediate solution, we are now manually running a modified version of the downsample_logging.py example script, where I have changed the output format of the CSV slightly to match the previous format used in the project.
I guess I’m both asking why this error is occuring and how I could have rewritten the code to avoid this. I’d rather put together some minimal code that does what we need for the project, rather than use the full example scripts provided on Github. I also somewhat struggle with understanding how and when I want to use StreamProcess and DataBuffer.
Other than this error, the Joulescope is just what we need for monitoring out hardware! So I have bought three this far ![]()